4. Learning
This matters because the core training loop is where theory turns into behavior. You need to see how forward passes, loss computation, backpropagation, and parameter updates fit together before higher-level abstractions make sense.
4.1. Training and testing
[1]:
from torchvision import datasets, models, transforms
import torch.optim as optim
import torch.nn as nn
from torchvision.transforms import *
from torch.utils.data import DataLoader
import torch
import numpy as np
from collections import defaultdict
import time
import copy
def train(dataloaders, model, criterion, optimizer, scheduler, device, num_epochs=20):
def format_start_stop(start, stop):
elapsed = stop - start
return f'{elapsed//60:.0f}m {elapsed%50:.0f}s'
best_model_weights = copy.deepcopy(model.state_dict())
best_acc = -1.0
loop_start = time.time()
for epoch in range(num_epochs):
train_loss, train_acc = 0.0, 0.0
test_loss, test_acc = 0.0, 0.0
train_start, test_start = 0.0, 0.0
train_stop, test_stop = 0.0, 0.0
for phase in ['train', 'test']:
if phase == 'train':
optimizer.step()
scheduler.step()
model.train()
train_start = time.time()
else:
model.eval()
test_start = time.time()
running_loss = 0.0
running_corrects = 0
n = 0
dataloader = dataloaders[phase]
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(phase == 'train'):
outputs = model(inputs)
loss = criterion(outputs, labels)
_, preds = torch.max(outputs, 1)
if phase == 'train':
loss.backward()
optimizer.step()
running_loss += loss.mean() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
n += len(labels)
epoch_loss = running_loss / float(n)
epoch_acc = running_corrects.double() / float(n)
if phase == 'train':
train_stop = time.time()
train_loss, train_acc = epoch_loss, epoch_acc
else:
test_stop = time.time()
test_loss, test_acc = epoch_loss, epoch_acc
if epoch_acc > best_acc:
best_model_weights = copy.deepcopy(model.state_dict())
best_acc = epoch_acc
train_time = format_start_stop(train_start, train_stop)
test_time = format_start_stop(test_start, test_stop)
train_metrics = f'TRAIN: {train_loss:.4f}, {train_acc:.4f}, {train_time}'
test_metrics = f'TEST: {test_loss:.4f}, {test_acc:.4f}, {test_time}'
print(f'epoch {str(epoch + 1).zfill(2)}/{str(num_epochs).zfill(2)} | {train_metrics} | {test_metrics}')
loop_stop = time.time()
loop_time = format_start_stop(loop_start, loop_stop)
print(f'completed learning in {loop_time}, best accuracy {best_acc:.4f}')
model.load_state_dict(best_model_weights)
return model
def get_dataloaders():
def clean_up(path):
import os
from shutil import rmtree
ipynb_checkpoints = f'{path}/.ipynb_checkpoints'
if os.path.exists(ipynb_checkpoints):
rmtree(ipynb_checkpoints)
def get_dataloader(phase):
path = f'./shapes/{phase}'
clean_up(path)
if phase in ['valid']:
transform = transforms.Compose([
Resize(224),
ToTensor()])
else:
transform = transforms.Compose([
Resize(224),
RandomAffine(degrees=(30, 50), shear=5),
ToTensor()])
image_folder = datasets.ImageFolder(path, transform=transform)
# print(path, image_folder.classes)
return DataLoader(image_folder, batch_size=4, shuffle=True, num_workers=4)
return {phase: get_dataloader(phase) for phase in ['train', 'test', 'valid']}
np.random.seed(37)
torch.manual_seed(37)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
pretrained=True
num_classes = 3
num_epochs = 5
dataloaders = get_dataloaders()
model = models.resnet18(pretrained=pretrained)
model.fc = nn.Linear(model.fc.in_features, num_classes)
model = model.to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Rprop(model.parameters(), lr=0.01)
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1)
model = train(dataloaders, model, criterion, optimizer, scheduler, device, num_epochs=num_epochs)
epoch 01/05 | TRAIN: 1.7014, 0.4333, 0m 1s | TEST: 3.1310, 0.2000, 0m 0s
epoch 02/05 | TRAIN: 1.1330, 0.6000, 0m 1s | TEST: 0.4330, 0.8667, 0m 0s
epoch 03/05 | TRAIN: 0.5296, 0.7667, 0m 1s | TEST: 0.2806, 0.9333, 0m 0s
epoch 04/05 | TRAIN: 0.3285, 0.8333, 0m 1s | TEST: 0.1385, 0.9333, 0m 0s
epoch 05/05 | TRAIN: 0.1591, 0.9333, 0m 1s | TEST: 0.1858, 0.9333, 0m 0s
completed learning in 0m 5s, best accuracy 0.9333
4.2. Validation
[2]:
import torch.nn.functional as F
def validate(model, dataloader):
results = []
truths = []
for inputs, labels in dataloader:
inputs = inputs.to(device)
labels = labels.to(device)
optimizer.zero_grad()
with torch.set_grad_enabled(False):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
probs = F.softmax(outputs, dim=1).cpu().detach().numpy()
truths.append(labels.cpu().detach().numpy())
results.append(probs)
return np.vstack(results), np.hstack(truths)
P, y = validate(model, dataloaders['valid'])
[3]:
P
[3]:
array([[9.9743372e-01, 2.5547585e-03, 1.1551682e-05],
[7.1126390e-03, 9.4026469e-02, 8.9886081e-01],
[9.9802750e-01, 1.8798379e-03, 9.2657341e-05],
[1.9885978e-02, 1.6604094e-02, 9.6350998e-01],
[2.6707968e-02, 5.7259339e-01, 4.0069860e-01],
[2.3591267e-02, 9.0400763e-02, 8.8600796e-01],
[6.3273758e-02, 3.6535725e-01, 5.7136893e-01],
[3.7592563e-01, 6.0811573e-01, 1.5958672e-02],
[5.6413960e-01, 4.2183867e-01, 1.4021679e-02],
[1.0327103e-01, 9.5645167e-02, 8.0108386e-01],
[6.3741702e-01, 3.6172977e-01, 8.5326034e-04],
[6.7647696e-01, 3.2323289e-01, 2.9013102e-04],
[8.6762629e-02, 5.0049621e-01, 4.1274115e-01],
[9.1324246e-01, 8.6728059e-02, 2.9449126e-05],
[1.7835042e-01, 3.9919698e-01, 4.2245257e-01]], dtype=float32)
[4]:
y
[4]:
array([0, 1, 0, 2, 1, 2, 1, 2, 2, 2, 0, 0, 1, 0, 1])
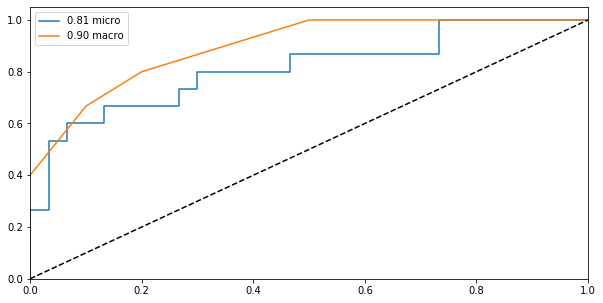
4.2.1. Micro-averaging
[5]:
from sklearn.metrics import roc_curve, auc
fpr = dict()
tpr = dict()
roc_auc = dict()
for i in range(num_classes):
fpr[i], tpr[i], _ = roc_curve([1 if label == i else 0 for label in y], P[:, i])
roc_auc[i] = auc(fpr[i], tpr[i])
y_test = np.array([[1 if label == i else 0 for label in y] for i in range(num_classes)]).ravel()
y_preds = P.T.ravel()
fpr['micro'], tpr['micro'], _ = roc_curve(y_test, y_preds)
roc_auc['micro'] = auc(fpr['micro'], tpr['micro'])
4.2.2. Macro-averaging
[6]:
all_fpr = np.unique(np.concatenate([fpr[i] for i in range(num_classes)]))
mean_tpr = np.zeros_like(all_fpr)
for i in range(num_classes):
mean_tpr += np.interp(all_fpr, fpr[i], tpr[i])
mean_tpr /= num_classes
fpr['macro'], tpr['macro'] = all_fpr, mean_tpr
roc_auc['macro'] = auc(fpr['macro'], tpr['macro'])
4.2.3. Visualize
[7]:
%matplotlib inline
import matplotlib.pyplot as plt
fig, ax = plt.subplots(figsize=(10, 5))
ax.plot(fpr['micro'], tpr['micro'], label=f'{roc_auc["micro"]:.2f} micro')
ax.plot(fpr['macro'], tpr['macro'], label=f'{roc_auc["macro"]:.2f} macro')
ax.plot([0, 1], [0, 1], 'k--')
ax.set_xlim([0, 1.0])
ax.set_ylim([0.0, 1.05])
ax.legend()
[7]:
<matplotlib.legend.Legend at 0x7f4358e55e80>